
Why are Databricks APIs relevant and how to use them?
Databricks notebooks can be scheduled to run with a Databricks job for a fixed interval. But what if the notebook needs to run based on random events which do not have a predictable pattern? Of course we can always go to the UI and trigger the job manually, but it would be better if this can be done automatically. Databricks Jobs API allows triggering an one-time run of a job and getting the run status for monitoring purposes without manually checking the UI. How are you tackling this kind of situation?
The benefits of using Databricks Jobs API
- Databricks Jobs API can create, modify, manage, list, trigger and check job runs using API requests without having to go to the UI and click around.
- Databricks Jobs API enables engineers to automate these processes with code and integrate them with other actions into a pipeline and make it easily scalable.
- Databricks Jobs API can be integrated with any language which can initiate a request.
- By integrating Databricks Jobs API with other tools, it allows event-based triggers for Databricks Jobs, which creates more efficient runs.
Use cases
It is not unusual that some tables are not updated on a regular basis. For example, tables storing configuration data or master data are unlikely to change very frequently. However, it is still important that these tables are updated when there is a data change. To update these tables timely, while consuming minimum effort and resources, we can use the Databricks Jobs API.
Databricks Jobs API can be invoked in many tools, such as Microsoft Azure DevOps pipelines, Azure Logic Apps and other applications. For example, we can automatically update Databricks workflow in an Azure DevOps pipeline, using configuration data stored in the repository and Databricks Jobs API. This means that whenever a change is made to the configuration data in the repository, the pipeline will be triggered to update the workflow using the Jobs API.
Using Databricks API in Python to trigger a job and monitor the run
We can trigger a job with a one-time run with notebook parameters using jobs/run-now API:
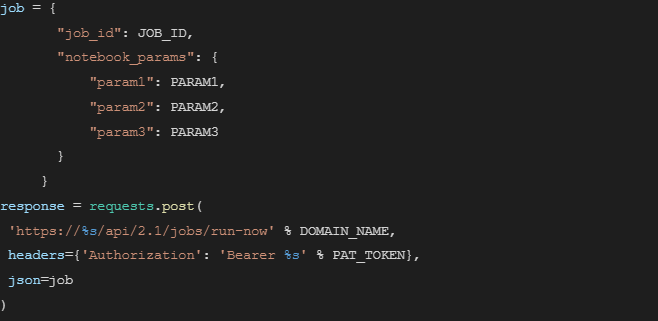
More settings could be provided along the JSON object job, such as idempotency_token and python_params. The full specs of Databricks Jobs API can be found here.
If the above API call is posted successfully, the response will return the run_id of the triggered run.
Note: It is a good idea to check the response of the API call. Because if the API call was not successfully posted, the error will be returned as text in the response and will not interrupt the running of code, which means the python script will not show an error.

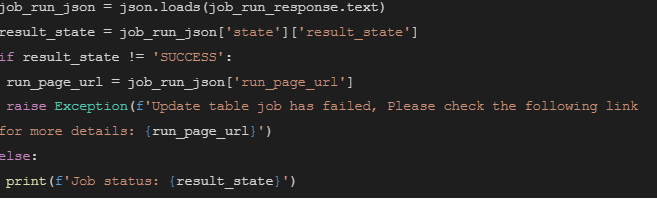
According to the return information of this API you can develop a piece of logic to check the status of the run.
In this case, if the result status is not successful, it will raise an error with a link to the failed run.
Databricks is winning more developers through enriching their APIs catalog
Some organizations are still using pipelines (or jobs) that are scheduled more frequently than that the tables are actually updated. This results in a waste of computing resources and cost. Some are using a less frequently scheduled pipeline (or job) where tables are updated more than expected. This results in delays in getting the most up-to-date information.
With Databricks Jobs APIs, near-real-time updates of infrequently updated tables become possible. In addition, there are other APIs provided by Databricks to ease the management of Databricks, such as workspace APIs and DBFS APIs.
The empowered Databricks APIs create a lot more possibilities with customization and automation of Databricks. This is where Devoteam comes in. Do you need an expert party to help you explore the benefits of using them in your organization? Please get in touch with us.

