In the world of Big Data, efficiency is paramount. As data scientists, we often find ourselves dealing with massive datasets spanning several years. Processing large volumes of data can be time-consuming and costly. However, with the right optimization techniques, we can significantly improve the efficiency of our data operations. In this blog post, I will share simple yet effective optimization strategies that I used in Databricks to reduce the processing time of a merge operation from 2 hours to just 2.5 minutes.

The Challenge
I was working with a dataset that spanned almost five years, with tens of billions of rows. My task was to perform a merge operation based on two conditions: matching timestamps and two other columns. The initial query looked something like this:

Despite the target table being optimized with ZORDER BY Timestamp,ColX running this query on such a large dataset was quite slow. It took around 2 hours to complete the merge operation, which was far from ideal. It’s important to note that all the operations were performed using Databricks runtime 13.3 and without enabling Photon.
The Optimization
To improve the speed of the merge operation, I decided to limit the search space by adding a condition to the ON clause. Instead of considering the entire target table for merge, I only focused on the data in the target table where the Timestamp column’s value is greater than or equal to the earliest date in the source table (start_date), usually two months in the past from the current date. So, instead of scanning data in the target table for all five years, only the last two months are scanned. The optimized query is as follows:
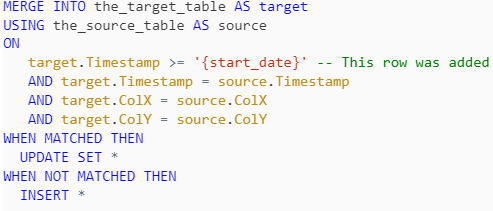
The Result
The result was very impressive. The optimized query reduced the merge time from 2 hours to just 11 minutes (a reduction of over 90%). Basically, by limiting the search space of the target table, Databricks was able to process the data much faster.
Remarkably, the performance improved significantly upon enabling Photon. The execution time was reduced from 11 minutes to a mere 2.5 minutes. Despite Photon being 2.5 times more expensive, it offered a substantial improvement factor of 4.4x, resulting in a cost reduction of 43%.
Analysis
Physical Plan
In the unoptimized merge query, the merge condition checks for matches based on the Timestamp, colX, and colY columns. This condition requires the engine to scan the entire target table to find matching rows, which can be time-consuming if the table is large.
(((Timestamp#2444 = Timestamp#674) AND (colX#2449 = colX#675)) AND (colY#2450 = colY#676))
In the optimized merge query, an additional clause is added to the merge condition: target.Timestamp >= ‘{start_date}’. This clause significantly reduces the search space by only considering rows where the Timestamp is greater than or equal to a certain date. This means the engine can skip scanning rows that are guaranteed not to match, resulting in a faster operation.
(((Timestamp#2444 >= 2023-10-01 00:00:00) AND (Timestamp#2444 = Timestamp#674)) AND ((colX#2449 = colX#675) AND (colY#2450 = colY#676)))
Z-Ordering Enhancement
Z-Ordering is a technique used in Delta Lake on Databricks to optimize the layout of data to improve query performance. When a table is Z-Ordered by a column (or a set of columns), Delta Lake ensures that the data in these columns is stored close together.
In our case, having the target table Z-Ordered by Timestamp means that all the data with the same or similar Timestamp values are stored close together. When a merge operation with a condition like target.Timestamp >= ‘{start_date}’ is executed, Databricks can quickly find the relevant area in the target table without having to scan the entire table. This is because it knows that all the data meeting this condition is located in the same set of files, thanks to Z-Ordering.
Photon
Photon is a high-performance, in-memory storage engine utilized by Databricks that significantly enhances merge statement speeds. Its efficiency stems from optimized data layouts and vectorized processing, enabling lightning-fast operations on large datasets.
Conclusion
This case study highlights the importance of optimization in data processing. Even simple changes, like limiting the search space and enabling features (like Photon in this case), can lead to significant improvements in efficiency. So, the next time you find yourself waiting for a query to run, consider whether there’s a way to optimize it. You might be surprised by how much time you can save!

